🎉 La Cava and Lett’s fair ML tool, Interfair, won first place ($250K) in the 2023 NIH Challenge, “Bias Detection Tools for Clinical Decision Making”.

Research
Our research focuses on developing machine learning methods and using them to explain the principles underlying complex, biomedical processes. We use these methods to learn predictive models from electronic health records (EHRs) that are both interpretable to clinicians and fair to the population on which they are deployed. Our long-term goals are to positively impact human health by developing methods that are flexible enough to automate entire computational workflows underlying scientific discovery and medicine.Overviews
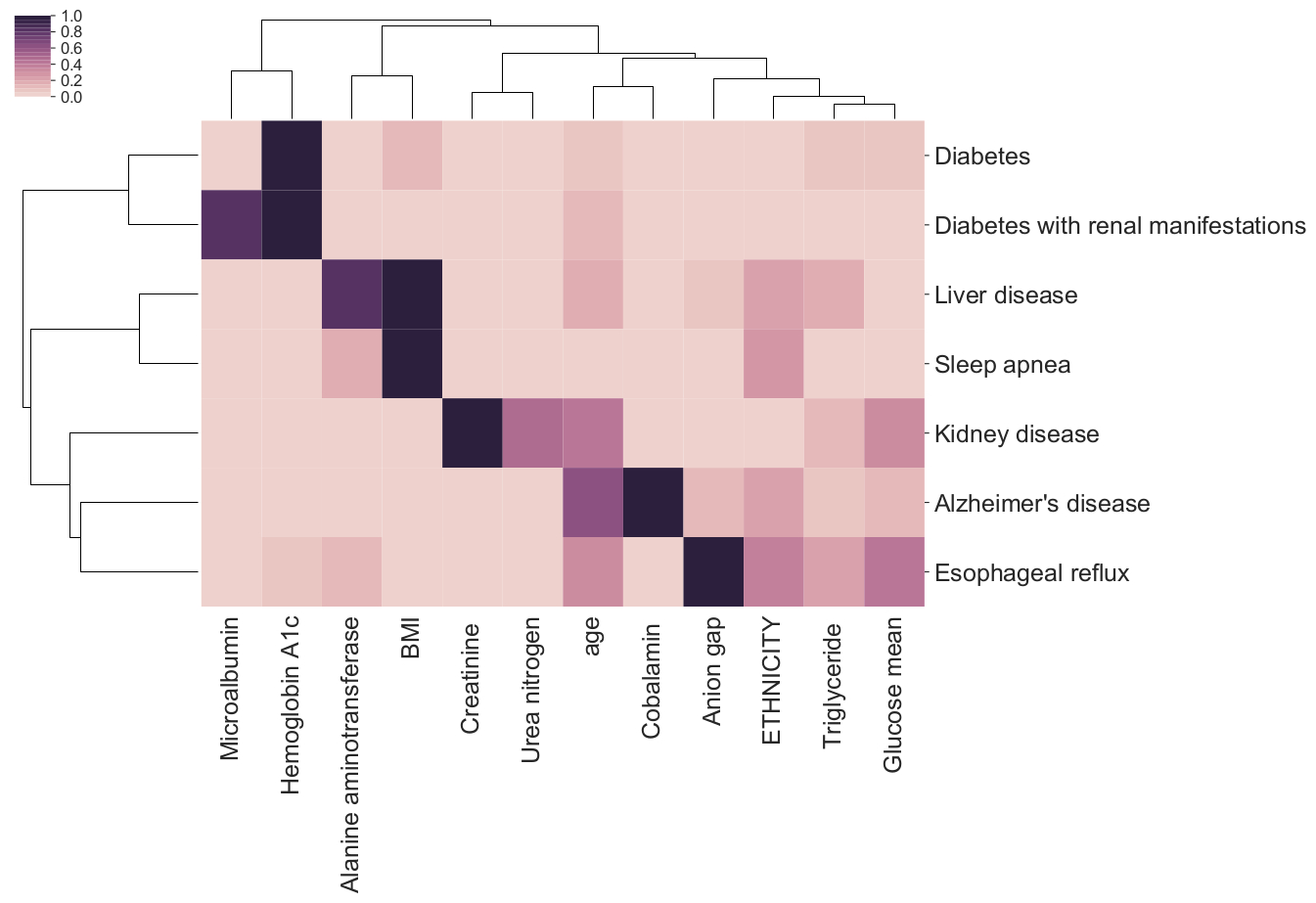
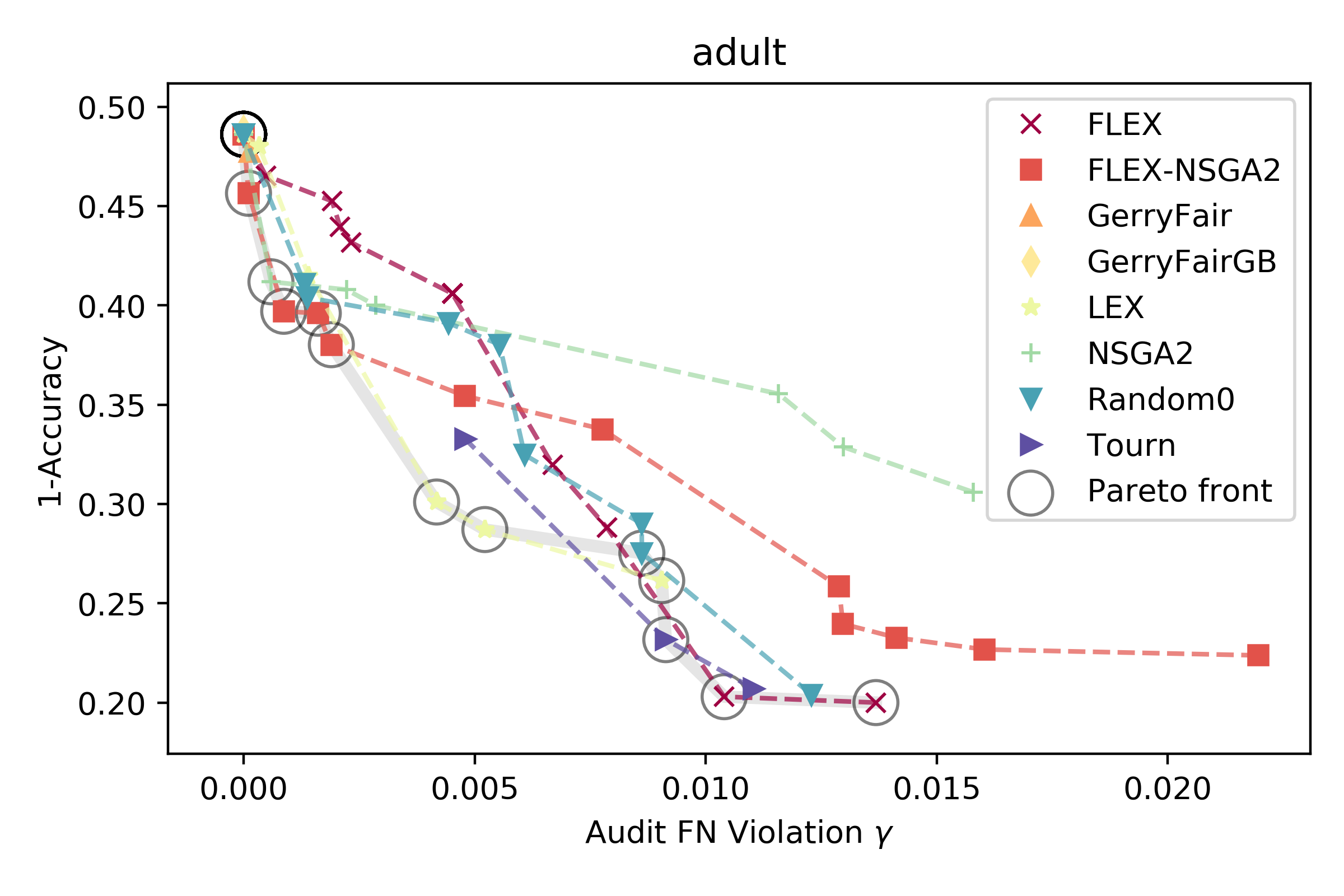
We study both black-box and glass-box ML methods to improve the intelligibility and/or explainability of models that are trained for clinical prediction task...
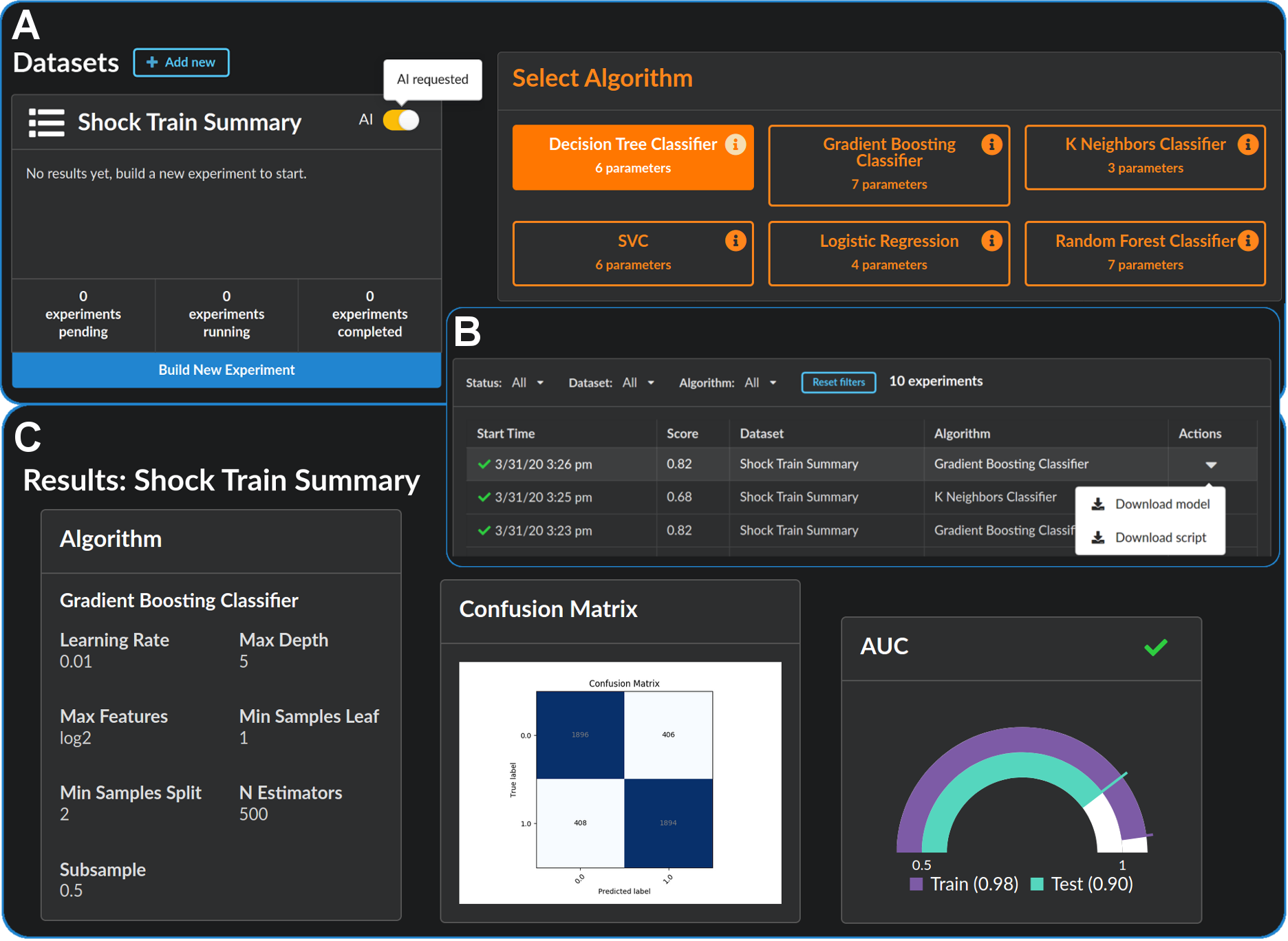
While artificial intelligence (AI) has become widespread, many commercial AI systems are not yet accessible to individual researchers nor the general public ...
See our publications and posts about them.