
Intelligible Predictive Models
We study both black-box and glass-box ML methods to improve the intelligibility and/or explainability of models that are trained for clinical prediction tasks using electronic health record (EHR) data. EHR data offer a promising opportunity for advancing the understanding of how clinical decisions and patient conditions interact over time to influence patient health. However, EHR data are difficult to use for predictive modeling due to the various data types they contain (continuous, categorical, text, etc.), their longitudinal nature, the high amount of non-random missingness for certain measurements, and other concerns. Furthermore, patient outcomes often have heterogeneous causes and require information to be synthesized from several clinical lab measures and patient visits. Researchers often resort to using complex, black-box predictive models to overcome these challenges, thereby introducing additional concerns of accountability, transparency and intelligibility.
Can’t we just explain black-box models?
Although black-box models are typically accurate, they are often bad at explaining how they arrive at those predictions, and may also disagree with very similar models about which factors are driving their predictive ability1.
Symbolic Regression for Interpretable Machine Learning
An alternative, and promising approach, is to use glass-box ML methods such as symbolic regression that can capture complex relationships in data and yet produce and intelligible final model. Symbolic regression methods jointly optimize structure of a model, as well as its parameters, usually with the goal of finding a simple and accurate symbolic model.
However, intelligibility is complicated to define, and is both context- and user-dependent. In general, the intelligibility of a model depends heavily on its representation, i.e, how it defines its feature space.
](/assets/images/rep_learning_demo_2d.svg)
What makes a representation good? At the minimum, a good representation produces a model with better generalization than a model trained only on the raw data attributes. In addition, a good representation teases apart the factors of variation in the data into independent components. Finally, an ideal representation is succinct so as to promote intelligibility. This means a representation should only have as many features as there are independent factors in the process, and each of those features should be digestible by the user. Many of our research projects center around these three motivations when designing novel algorithms for interpretable machine learning.
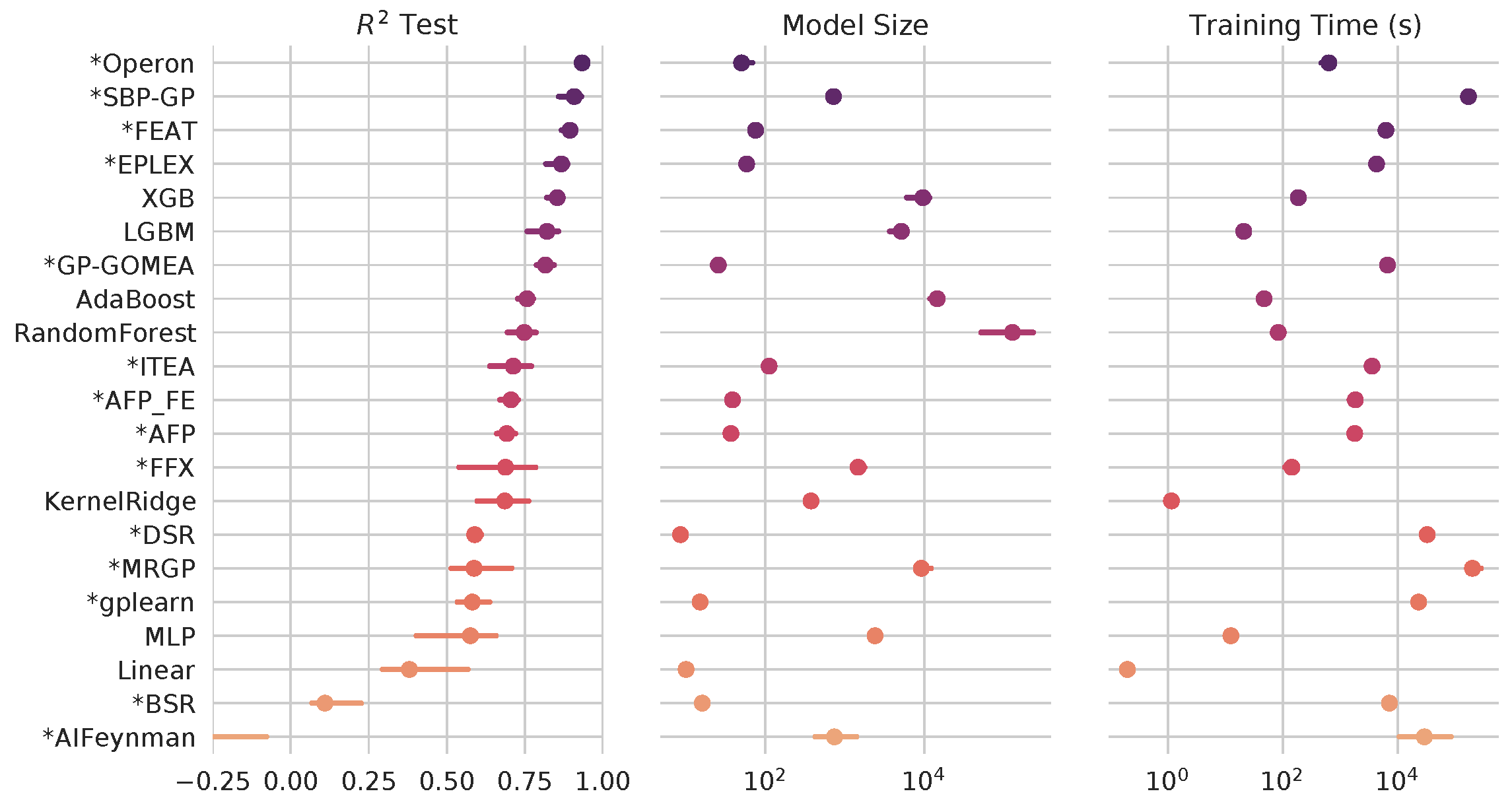
Can a simple symbolic model be accurate?
Researchers often see the complexity of a model as a trade-off with its error: more complex models should give better predictions than simple ones. However, very rarely is the nature of the trade-off actually characterized in a robust way.
In fact, what we have found is that for many tasks, symbolic regression approaches can perform as well as or better than state-of-the-art black-box approaches - and still produce simpler expressions2.
Do they work in clinical care?
Our preliminary work on symbolic regression approaches to patient phenotyping have shown success in producing accurate and interpretable models of treatment resistant hypertension3. More work is needed to scale and study these algorithms in routine clinical care.
